Что представляют собой стихи Книги Бытия 1:1-2:3: историческое повествование (где слова употреблены в прямом смысле, а последовательность событий соответствует реальному времени) или поэтическую метафору? Ответ на этот жизненно важный вопрос был целью моих исследований в рамках проекта RATE, результаты которых скоро будут изданы в виде отдельной главы в книге, посвященной этому проекту1. Здесь я привожу некоторые примеры наиболее поразительных результатов моей работы: данные параллельных текстов, контрольные графики, логистическая регрессия.
Приоритет текста: статистический подход
Хотя обычная морфология, синтаксис и лексика древнееврейского текста первых глав Библии не дают никаких оснований полагать, что мы имеем дело с чем-то иным, нежели простое повествование, многие приверженцы теории «старой Земли» считают эти главы поэтическим текстом. Насколько оправдан такой подход? Я убежден, что текст сам показывает нам, считал его автор поэзией или прозой: количественные лингвистические свойства, проявляющиеся при статистическом анализе, могут подсказать нам, какой смысл интуитивно вкладывали в него первые читатели2. В поисках ответа на этот вопрос я занялся изучением встречаемости в тексте Библии древнееврейских спрягаемых глаголов (глаголов, спрягающихся по лицам, родам и числам).
Из 48 прозаических и 49 поэтических текстов я сделал статистически достоверную случайную выборку, которую затем подверг статистическим тестам с целью ответить на два вопроса:
(1) Зависит ли от жанра (поэзия или проза) состав спрягаемых глаголов? и (2) Если да, то можно ли по нему определить жанр текста?3
Данные парных текстов
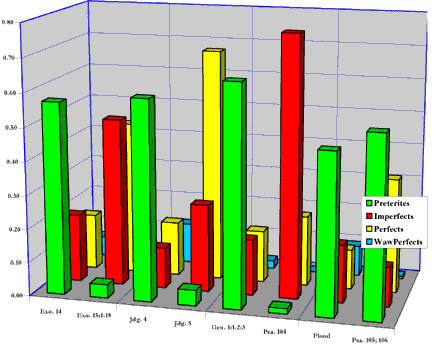 |
Контрольные графики
В контрольных графиках точки данных в пределах трех стандартных отклонений от средней имеют 99,73% вероятность принадлежности к данной выборке, а точки за пределами этих контрольных величин к выборке, скорее всего, не принадлежат. Графики показывают, что среднее значение соотношений между претеритными и всеми спрягаемыми глаголами у прозы и поэзии различается. Таким образом, состав спрягаемых глаголов зависит от жанра. Более того, стихи Бытия 1:1-2:3 находятся далеко за контрольными пределами для поэтических текстов и, следовательно, не относятся к этой группе.
Логистическая регрессия: оценка модели
Логистическая регрессия идеально подходит к нашим данным, поскольку всякий текст относится либо к поэзии, либо к прозе с вероятностью (P) соответственно 1 или 05. Мы рассчитали коэффициенты уравнения кривой, соответствующей этим нелинейным данным, найдя максимум для логарифма соотношения (P/(1-P)) для отношений претеритных глаголов ко всем спрягаемым в 97 проанализированных текстов6.
Для определения качества модели мы провели расчет критерия «хи-квадрат», чтобы проверить нулевую гипотезу о том, что наша модель не лучше модели с нулевыми коэффициентами7. Расчет позволил отвергнуть нулевую гипотезу на высоком статистически достоверном уровне8.
Мы также определили R2, меру достоверности модели, которая показывает, насколько модель уменьшает разброс по сравнению с моделью с нулевыми коэффициентами. R2 варьирует от 0 (плохая модель) до 1 (совершенная модель).9 Для нашей модели R2 был равен 0,85 для невзвешенной, 0,88 для взвешенной – очень хорошие показатели.
Логистическая регрессия: точность классификации
Совершенная классификационая модель должна верно классифицировать по жанру все тексты. Наша модель неверно классифицировала лишь 2 текста из 97.
На точность классификации указывает пропорциональное изменение ошибки (tp),id которое показывает, насколько модель уменьшает ошибку:
tp = ((ошибки без применения модели) -(ошибки с применением модели))/(ошибки без применения модели).
Ожидаемое число ошибок без применения модели для классификационной модели равно
2nY=0nY=1/Af,
где nY=0 is – число проанализированных поэтических текстов, nY=1 – число проанализированных прозаических текстов, N – общее число проанализированных текстов.
Если tp равно 1, то классификационная модель совершенна; если tpменьше нуля, то модель работает хуже, чем случайная классификация. Для нашей модели Tp была равна 0,96, то есть была высоко достоверна.11
Для проверки нулевой гипотезы о том, что доля случаев, неверно классифицируемых моделью, была не ниже, чем при случайной классификации, была использована биномиальная статистика. Наша модель отвергла и эту нулевую гипотезу на высоко достоверном уровне12. Итак, наша модель отлично классифицирует тексты.
Логистическая регрессия: определение жанра текста
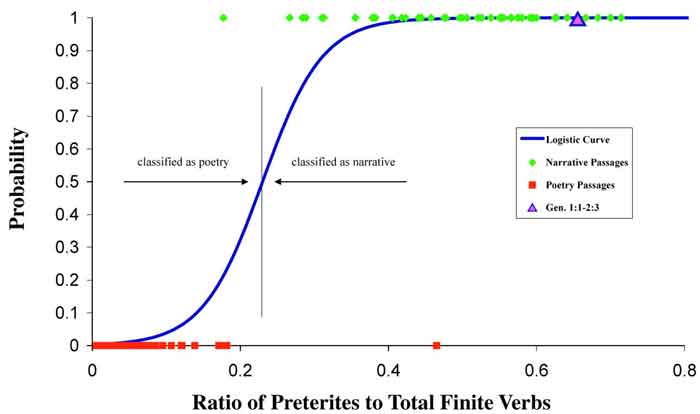 |
Вывод
Соотношение претеритных глаголов и спрягаемых глаголов в древнееврейской прозе и поэзии существенно различается. Модель логистической регрессии, примененная к соотношению претеритных глаголов к спрягаемым глаголам, позволяет отнести тексты к поэзии или прозе с высочайшим уровнем точности. С практически 100% вероятностью стихи Бытия 1:1-2:3 по этому критерию относятся к прозе, а не поэзии.
Три главных вывода из этой работы: (1) статистически недоказуемо, что стихи Быт. 1:1-2:3 – это поэзия; (2) поскольку Быт. 1:1-2:3 – это проза, эти стихи следует читать, как все остальное древнееврейское повествование – как точное изложение исторических событий, ставящее целью донести безошибочное богословское послание13; (3) поскольку этот текст - проза, то есть только одна надежная точка зрения на его смысл: Бог сотворил все сущее за шесть календарных дней.
Примечания и литература
1. Проект RATE («Радиоизотопы и возраст Земли» – "Radioisotopes and the Age of The Earth") – это научно-исследовательский проект, начатый в 1997 году совместно Институтом креационных исследований, Креационным научным обществом и миссией «Ответы Бытия».2. О том, как взаимоотношения автора с первыми читателями могут отразиться на восприятии текста, см. Nicolai Winther-Nielsen, "Fact, Fiction and Language Use: Can Modern Pragmatics Improve on Halpern's Case for History in Judges?" in V. Phillips Long et al, eds. Windows into Old Testament History: Evidence, Argument, and the Crisis of "Biblical Israel" (Grand Rapids: Wm. B. Eerdmans Publishing Co., 2002), pp. 44-81.
3. Доктор Роджер Лонгботэм (Roger Longbotham), старший статистик сайта Amazon.com, предоставил для этого исследования консультации по статистике.
4. Претериты формируют «основу» древнееврейской прозы. See among others Jerome Walsh, Style and Structure in Biblical Hebrew Narrative (Collegeville, Minnesota: The Liturgical Press, 1996), pp. 155-172.
5. Scott Menard, Applied Logistic Regression, 2nd Edition (Thousand Oaks, California: Sage Publications, 2002), pp. 67-91 и Fred Pampel, Logistic Regression: A Primer (Thousand Oaks, California: Sage Publications, 2000), pp. 1-18.
6. В модели X, (претериты/спрягаемые) -5.39 + 22.44 X для невзвешенных данных -5.69 + 24.73 X для взвешенных данных.
7. Menard, pp. 17-22.
8. Для двух хвостов распределения p < 0,000001.
9. Menard, p. 24.
10. Ibid., pp. 28-40.
11. Для наших данных ожидаемые ошибки без применения модели равны 2(48)(49)/97, то есть 48,49. Отсюда tp= (48,49 - 2)748,49 = 0,96.
12. Биномиальная статистика была рассчитана следующим образом: d = (Pe-p) I VP,(1 -P)IN~ где Pe равно (ошибки без модели)/7V, а pe равно (ошибки с моделью)/AO-Для нашей модели d было равно 9.44167264. Отсюда p< 1.0 x 10 14.
13. Meir Sternberg, The Poetics of Biblical Narrative: Ideological Literature and the Drama of Reading (Bloomington: Indiana University Press, 1987), p. 31.
© 2004 by ICR • All Rights Reserved
Перевод А. Мусиной
18 сентября 2006 г.